
이야기 | DeepSeek Expands with Competitive Salaries Amid AI Boom
페이지 정보
작성자 Boyd 작성일25-03-19 14:26 조회126회 댓글0건본문
While particular languages supported are usually not listed, DeepSeek Coder is trained on an enormous dataset comprising 87% code from multiple sources, suggesting broad language assist. It is trained on 2T tokens, composed of 87% code and 13% pure language in both English and Chinese, and is available in various sizes as much as 33B parameters. Yes, the 33B parameter mannequin is too massive for loading in a serverless Inference API. In 2024, the big model business remains both unified and disrupted. OpenSourceWeek: DeepEP Excited to introduce DeepEP - the first open-source EP communication library for MoE mannequin training and inference. However, it can be launched on devoted Inference Endpoints (like Telnyx) for scalable use. Yes, DeepSeek Coder supports industrial use beneath its licensing settlement. Free Deepseek Online chat for industrial use and absolutely open-source. The "expert models" were skilled by beginning with an unspecified base model, then SFT on both knowledge, and synthetic information generated by an inside DeepSeek-R1-Lite model. By including the directive, "You need first to put in writing a step-by-step outline and then write the code." following the preliminary prompt, we have now observed enhancements in efficiency. That is a mix of H100's, H800's, and H20's, in accordance with SemiAnalysis, including as much as 50k total.
 This training course of was accomplished at a complete value of around $5.57 million, a fraction of the expenses incurred by its counterparts. The low price of coaching and operating the language mannequin was attributed to Chinese firms' lack of access to Nvidia chipsets, which were restricted by the US as part of the continued trade struggle between the 2 nations. I believe one in every of the massive questions is with the export controls that do constrain China's entry to the chips, which that you must fuel these AI techniques, is that hole going to get larger over time or not? I feel it's a work in progress. Perhaps essentially the most notable facet of China’s tech sector is its long-practiced "996 work regime" - 9 a.m. Yes, China’s DeepSeek AI will be integrated into your online business app to automate duties, generate code, analyze knowledge, and enhance resolution-making. He believes China’s massive models will take a unique path than those of the mobile web period.
This training course of was accomplished at a complete value of around $5.57 million, a fraction of the expenses incurred by its counterparts. The low price of coaching and operating the language mannequin was attributed to Chinese firms' lack of access to Nvidia chipsets, which were restricted by the US as part of the continued trade struggle between the 2 nations. I believe one in every of the massive questions is with the export controls that do constrain China's entry to the chips, which that you must fuel these AI techniques, is that hole going to get larger over time or not? I feel it's a work in progress. Perhaps essentially the most notable facet of China’s tech sector is its long-practiced "996 work regime" - 9 a.m. Yes, China’s DeepSeek AI will be integrated into your online business app to automate duties, generate code, analyze knowledge, and enhance resolution-making. He believes China’s massive models will take a unique path than those of the mobile web period.
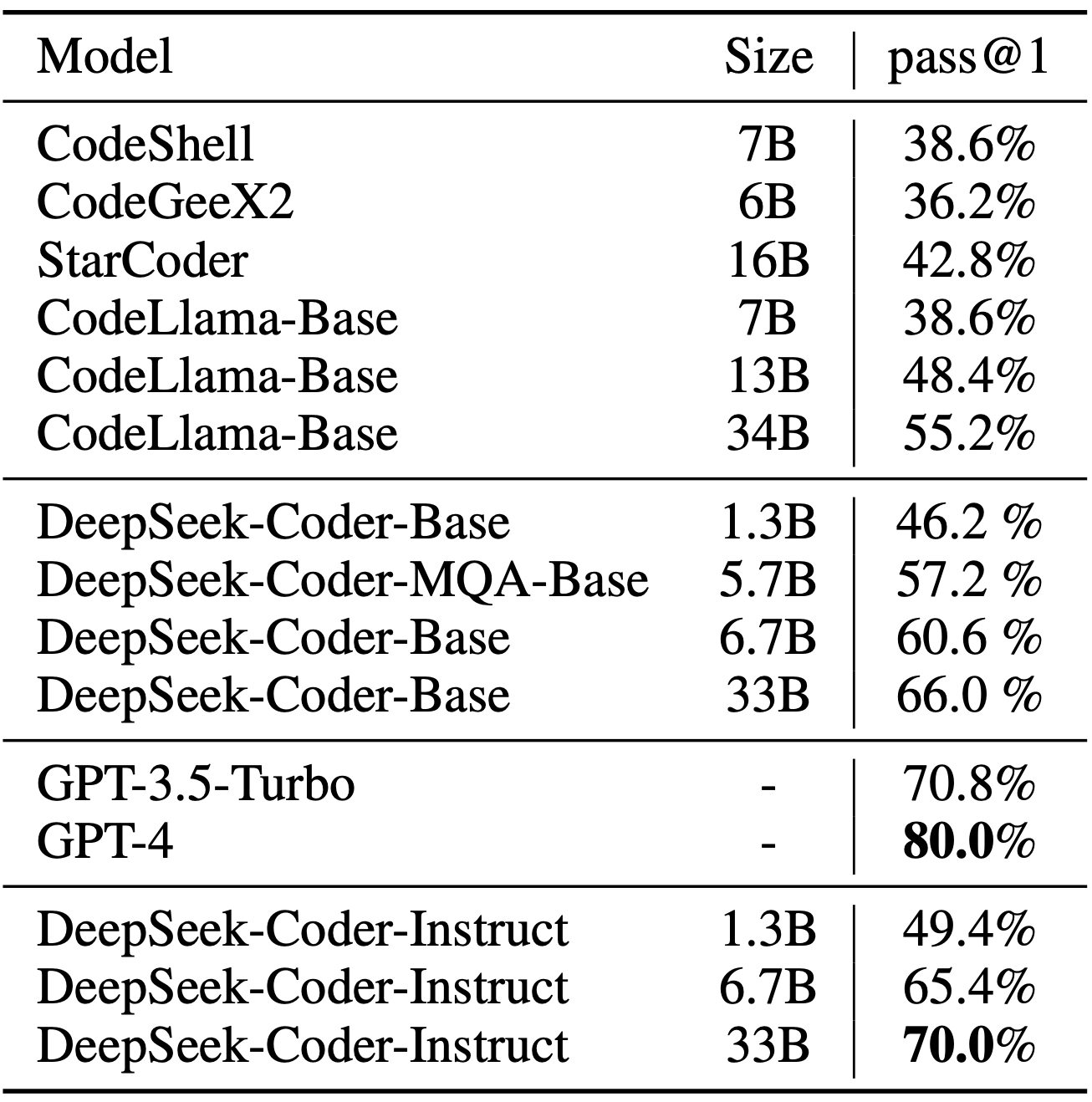
Is the model too massive for serverless applications? This model is designed to course of large volumes of information, uncover hidden patterns, and provide actionable insights. The DeepSeek-Coder-Instruct-33B model after instruction tuning outperforms GPT35-turbo on HumanEval and achieves comparable outcomes with GPT35-turbo on MBPP. This model achieves state-of-the-artwork performance on multiple programming languages and benchmarks. DeepSeek Coder is a capable coding mannequin educated on two trillion code and pure language tokens. Nous-Hermes-Llama2-13b is a state-of-the-artwork language model superb-tuned on over 300,000 directions. The model excels in delivering accurate and contextually related responses, makontact with us at our web-page.
댓글목록
등록된 댓글이 없습니다.