
정보 | 9 Odd-Ball Recommendations on Deepseek Ai News
페이지 정보
작성자 Francis 작성일25-03-11 03:24 조회81회 댓글0건본문
 As the AI discipline continues to evolve, models like DeepSeek-R1 exemplify the speedy advancements and the potential for innovation on this dynamic area. It has been broadly adopted throughout different industries and continues to be a benchmark for conversational AI fashions. DeepSeek’s versatile AI and machine learning capabilities are driving innovation throughout varied industries. As of 2025, these models symbolize the forefront of AI-pushed natural language processing (NLP), every providing unique capabilities and options. "Despite their apparent simplicity, these problems often involve complicated solution techniques, making them wonderful candidates for constructing proof data to enhance theorem-proving capabilities in Large Language Models (LLMs)," the researchers write. These stockpiled chips have enabled Chinese AI firms to prepare models on GPUs (e.g. H100, H800, and A100) not too inferior to those that U.S. The model was educated utilizing approximately 2,000 Nvidia H800 chips over fifty five days, costing around $5.6 million. DeepSeek, a startup AI company owned by a Chinese hedge fund, which is in turn owned by a young AI whiz-child, Liang Wenfeng, claims that its newly launched V-3 software-R1 was trained inexpensively and with out using NVIDIA’s high-finish chips, the ones that can't be exported to China.
As the AI discipline continues to evolve, models like DeepSeek-R1 exemplify the speedy advancements and the potential for innovation on this dynamic area. It has been broadly adopted throughout different industries and continues to be a benchmark for conversational AI fashions. DeepSeek’s versatile AI and machine learning capabilities are driving innovation throughout varied industries. As of 2025, these models symbolize the forefront of AI-pushed natural language processing (NLP), every providing unique capabilities and options. "Despite their apparent simplicity, these problems often involve complicated solution techniques, making them wonderful candidates for constructing proof data to enhance theorem-proving capabilities in Large Language Models (LLMs)," the researchers write. These stockpiled chips have enabled Chinese AI firms to prepare models on GPUs (e.g. H100, H800, and A100) not too inferior to those that U.S. The model was educated utilizing approximately 2,000 Nvidia H800 chips over fifty five days, costing around $5.6 million. DeepSeek, a startup AI company owned by a Chinese hedge fund, which is in turn owned by a young AI whiz-child, Liang Wenfeng, claims that its newly launched V-3 software-R1 was trained inexpensively and with out using NVIDIA’s high-finish chips, the ones that can't be exported to China.
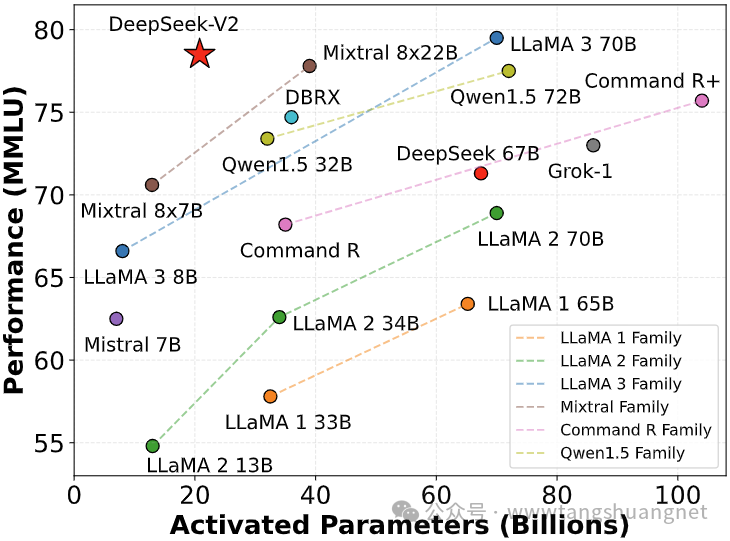 Because the U.S. private industrial AI producers are heavily reliant on overseas AI skills - H-1B holders from China and so on - to what - to what extent do you assume enforcement will likely be doable? "In the primary stage, two separate specialists are skilled: one that learns to rise up from the bottom and one other that learns to attain towards a hard and fast, random opponent. I'm stunned that DeepSeek R1 beat ChatGPT in our first face-off. DeepSeek Coder (November 2023): DeepSeek introduced its first model, DeepSeek Coder, an open-source code language model trained on a various dataset comprising 87% code and 13% pure language in both English and Chinese. ChatGPT's coaching, while leading to a highly capable model, involved substantially higher computational assets and associated costs. Then again, it is now concerning the sources used for Qwen 2.5 however it will probably handle advanced duties and lengthy conversations with a give attention to efficiency and scalability. It’s too quickly to say, but it’s now evident that America and China are in a tight race to harness the facility of A.I. Claude now permits you to add content straight from Google Docs to chats and projects via a hyperlink.
Because the U.S. private industrial AI producers are heavily reliant on overseas AI skills - H-1B holders from China and so on - to what - to what extent do you assume enforcement will likely be doable? "In the primary stage, two separate specialists are skilled: one that learns to rise up from the bottom and one other that learns to attain towards a hard and fast, random opponent. I'm stunned that DeepSeek R1 beat ChatGPT in our first face-off. DeepSeek Coder (November 2023): DeepSeek introduced its first model, DeepSeek Coder, an open-source code language model trained on a various dataset comprising 87% code and 13% pure language in both English and Chinese. ChatGPT's coaching, while leading to a highly capable model, involved substantially higher computational assets and associated costs. Then again, it is now concerning the sources used for Qwen 2.5 however it will probably handle advanced duties and lengthy conversations with a give attention to efficiency and scalability. It’s too quickly to say, but it’s now evident that America and China are in a tight race to harness the facility of A.I. Claude now permits you to add content straight from Google Docs to chats and projects via a hyperlink.
Cerebras FLOR-6.3B, Allen AI OLMo 7B, Google TimesFM 200M, AI Singapore Sea-Lion 7.5B, ChatDB Natural-SQL-7B, Brain GOODY-2, Alibaba Qwen-1.5 72B, Google DeepMind Gemini 1.5 Pro MoE, Google DeepMind Gemma 7B, Reka AI Reka Flash 21B, Reka AI Reka Edge 7B, Apple Ask 20B, Reliance Hanooman 40B, Mistral AI Mistral Large 540B, Mistral AI Mistral Small 7B, ByteDance 175B, ByteDance 530B, HF/ServiceNow StarCoder 2 15B, HF Cosmo-1B, SambaNova Samba-1 1.4T CoE. MAX helps PyTorch and HuggingFace models out of the fatGPT totally free?
댓글목록
등록된 댓글이 없습니다.