
정보 | Winning Tactics For Deepseek
페이지 정보
작성자 Phillis Milton 작성일25-03-10 20:59 조회90회 댓글0건본문
 If you’re on the lookout for a solution tailored for enterprise-stage or niche applications, DeepSeek is likely to be extra advantageous. • We'll constantly iterate on the amount and quality of our training information, and discover the incorporation of further coaching sign sources, aiming to drive knowledge scaling across a extra comprehensive range of dimensions. Importantly, as a result of this type of RL is new, we're still very early on the scaling curve: the amount being spent on the second, RL stage is small for all gamers. On the factual benchmark Chinese SimpleQA, DeepSeek-V3 surpasses Qwen2.5-72B by 16.4 points, regardless of Qwen2.5 being skilled on a larger corpus compromising 18T tokens, which are 20% greater than the 14.8T tokens that DeepSeek-V3 is pre-trained on. When I used to be done with the basics, I used to be so excited and couldn't wait to go extra. This strategy not only aligns the model more intently with human preferences but in addition enhances performance on benchmarks, especially in situations the place out there SFT data are restricted. Combined with the framework of speculative decoding (Leviathan et al., 2023; Xia et al., 2023), it could possibly considerably speed up the decoding velocity of the model.
If you’re on the lookout for a solution tailored for enterprise-stage or niche applications, DeepSeek is likely to be extra advantageous. • We'll constantly iterate on the amount and quality of our training information, and discover the incorporation of further coaching sign sources, aiming to drive knowledge scaling across a extra comprehensive range of dimensions. Importantly, as a result of this type of RL is new, we're still very early on the scaling curve: the amount being spent on the second, RL stage is small for all gamers. On the factual benchmark Chinese SimpleQA, DeepSeek-V3 surpasses Qwen2.5-72B by 16.4 points, regardless of Qwen2.5 being skilled on a larger corpus compromising 18T tokens, which are 20% greater than the 14.8T tokens that DeepSeek-V3 is pre-trained on. When I used to be done with the basics, I used to be so excited and couldn't wait to go extra. This strategy not only aligns the model more intently with human preferences but in addition enhances performance on benchmarks, especially in situations the place out there SFT data are restricted. Combined with the framework of speculative decoding (Leviathan et al., 2023; Xia et al., 2023), it could possibly considerably speed up the decoding velocity of the model.
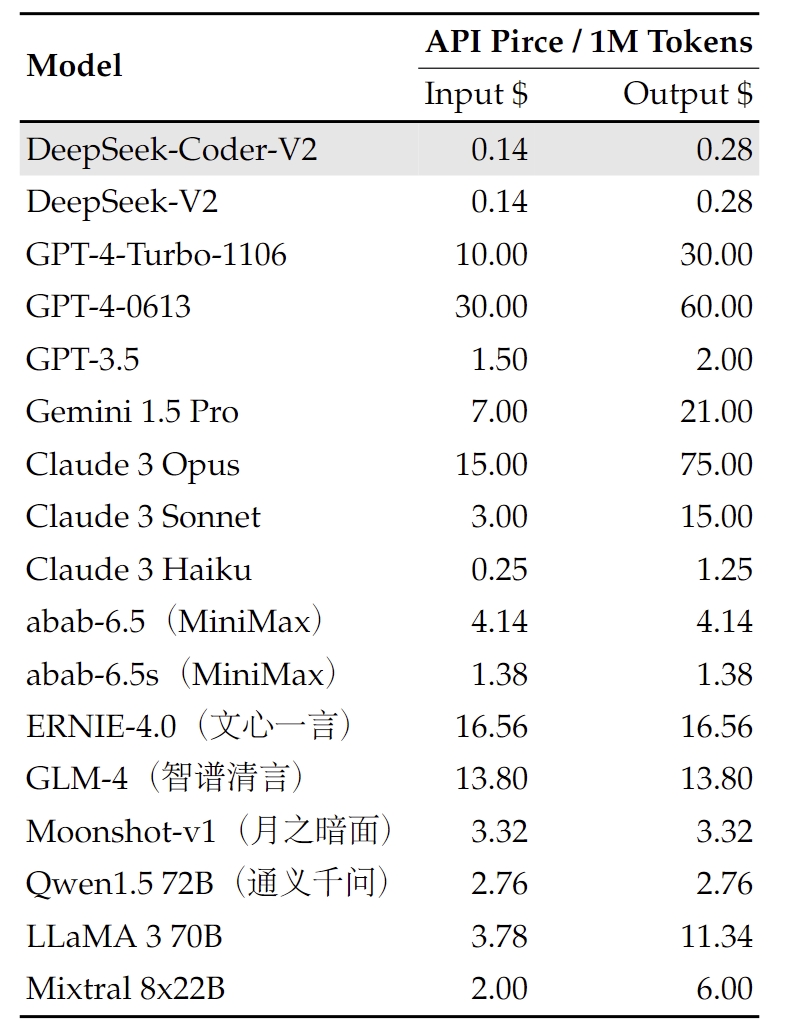 Multi-Token Prediction (MTP): Boosts inference effectivity and pace. For attention, we design MLA (Multi-head Latent Attention), which makes use of low-rank key-worth union compression to remove the bottleneck of inference-time key-worth cache, thus supporting environment friendly inference. Alternatives: - AMD GPUs supporting FP8/BF16 (via frameworks like SGLang). Singe: leveraging warp specialization for top performance on GPUs. Our objective is to stability the excessive accuracy of R1-generated reasoning information and the clarity and conciseness of often formatted reasoning information. This high acceptance fee permits DeepSeek-V3 to realize a considerably improved decoding velocity, delivering 1.8 times TPS (Tokens Per Second). Based on our evaluation, the acceptance fee of the second token prediction ranges between 85% and 90% throughout numerous generation topics, demonstrating consistent reliability. On Arena-Hard, DeepSeek-V3 achieves an impressive win price of over 86% in opposition to the baseline GPT-4-0314, performing on par with prime-tier fashions like Claude-Sonnet-3.5-1022. As well as, on GPQA-Diamond, a PhD-stage evaluation testbed, DeepSeek-V3 achieves remarkable results, ranking simply behind Claude 3.5 Sonnet and outperforming all different rivals by a considerable margin. It achieves a powerful 91.6 F1 score in the 3-shot setting on DROP, outperforming all other models in this class.
Multi-Token Prediction (MTP): Boosts inference effectivity and pace. For attention, we design MLA (Multi-head Latent Attention), which makes use of low-rank key-worth union compression to remove the bottleneck of inference-time key-worth cache, thus supporting environment friendly inference. Alternatives: - AMD GPUs supporting FP8/BF16 (via frameworks like SGLang). Singe: leveraging warp specialization for top performance on GPUs. Our objective is to stability the excessive accuracy of R1-generated reasoning information and the clarity and conciseness of often formatted reasoning information. This high acceptance fee permits DeepSeek-V3 to realize a considerably improved decoding velocity, delivering 1.8 times TPS (Tokens Per Second). Based on our evaluation, the acceptance fee of the second token prediction ranges between 85% and 90% throughout numerous generation topics, demonstrating consistent reliability. On Arena-Hard, DeepSeek-V3 achieves an impressive win price of over 86% in opposition to the baseline GPT-4-0314, performing on par with prime-tier fashions like Claude-Sonnet-3.5-1022. As well as, on GPQA-Diamond, a PhD-stage evaluation testbed, DeepSeek-V3 achieves remarkable results, ranking simply behind Claude 3.5 Sonnet and outperforming all different rivals by a considerable margin. It achieves a powerful 91.6 F1 score in the 3-shot setting on DROP, outperforming all other models in this class.
What's the capacity of DeepSeek fashions? Is DeepSeek Safe to use? Here give some examples of how to make use of our mannequin. With AWS, you need to use DeepSeek-R1 fashions to construct, experiment, and responsibly scale your generative AI ideas by using this powerful, value-efficientas been a sizzling matter at the tip of 2024 and the beginning of 2025 due to two particular AI models. These fashions present promising results in generating high-high quality, area-specific code. Evaluating massive language models educated on code. Based on Clem Delangue, the CEO of Hugging Face, one of many platforms internet hosting DeepSeek’s fashions, builders on Hugging Face have created over 500 "derivative" fashions of R1 which have racked up 2.5 million downloads mixed. As an illustration, certain math problems have deterministic outcomes, and we require the mannequin to supply the final answer within a chosen format (e.g., in a box), permitting us to use guidelines to verify the correctness. In lengthy-context understanding benchmarks equivalent to DROP, LongBench v2, and FRAMES, DeepSeek-V3 continues to show its place as a top-tier mannequin. LongBench v2: Towards deeper understanding and reasoning on realistic lengthy-context multitasks. The lengthy-context capability of DeepSeek-V3 is further validated by its best-in-class performance on LongBench v2, a dataset that was released only a few weeks earlier than the launch of Free DeepSeek Ai Chat V3.
댓글목록
등록된 댓글이 없습니다.