
불만 | Fighting For Deepseek: The Samurai Way
페이지 정보
작성자 Kiara 작성일25-03-01 10:22 조회72회 댓글0건본문
 If DeepSeek continues to innovate and address consumer wants successfully, it could disrupt the search engine market, offering a compelling different to established gamers like Google. But how does it compare to different widespread AI fashions like GPT-4, Claude, and Gemini? From the user’s perspective, its operation is much like different fashions. The 2 V2-Lite models have been smaller, and skilled equally. Then, with each response it provides, you've gotten buttons to copy the text, two buttons to rate it positively or negatively depending on the quality of the response, and another button to regenerate the response from scratch primarily based on the identical immediate. DeepSeek Coder comprises a collection of code language fashions skilled from scratch on both 87% code and 13% natural language in English and Chinese, with every mannequin pre-trained on 2T tokens. Accuracy reward was checking whether or not a boxed reply is right (for math) or whether or not a code passes tests (for programming). From the AWS Inferentia and Trainium tab, copy the example code for deploy DeepSeek-R1-Distill models. They later integrated NVLinks and NCCL, to train larger models that required mannequin parallelism. The primary challenge is naturally addressed by our training framework that uses giant-scale professional parallelism and data parallelism, which guarantees a large measurement of each micro-batch.
If DeepSeek continues to innovate and address consumer wants successfully, it could disrupt the search engine market, offering a compelling different to established gamers like Google. But how does it compare to different widespread AI fashions like GPT-4, Claude, and Gemini? From the user’s perspective, its operation is much like different fashions. The 2 V2-Lite models have been smaller, and skilled equally. Then, with each response it provides, you've gotten buttons to copy the text, two buttons to rate it positively or negatively depending on the quality of the response, and another button to regenerate the response from scratch primarily based on the identical immediate. DeepSeek Coder comprises a collection of code language fashions skilled from scratch on both 87% code and 13% natural language in English and Chinese, with every mannequin pre-trained on 2T tokens. Accuracy reward was checking whether or not a boxed reply is right (for math) or whether or not a code passes tests (for programming). From the AWS Inferentia and Trainium tab, copy the example code for deploy DeepSeek-R1-Distill models. They later integrated NVLinks and NCCL, to train larger models that required mannequin parallelism. The primary challenge is naturally addressed by our training framework that uses giant-scale professional parallelism and data parallelism, which guarantees a large measurement of each micro-batch.
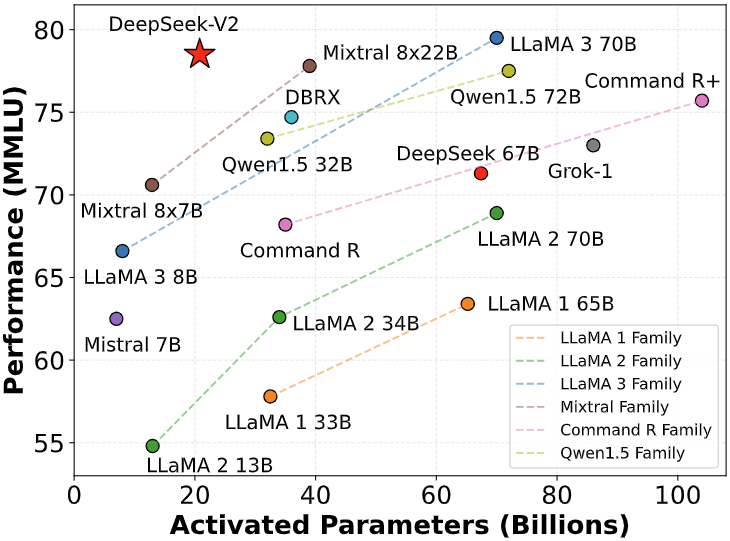 Program synthesis with massive language models. Yarn: Efficient context window extension of massive language models. The fashions can then be run on your own hardware using instruments like ollama. With this AI mannequin, you can do practically the same things as with different fashions. However, it has the identical flexibility as other models, and you may ask it to elucidate things more broadly or adapt them to your needs. Combined with the framework of speculative decoding (Leviathan et al., 2023; Xia et al., 2023), it could possibly considerably speed up the decoding pace of the mannequin. Standardized exams embody AGIEval (Zhong et al., 2023). Note that AGIEval consists of both English and Chinese subsets. Table 8 presents the performance of these fashions in RewardBench (Lambert et al., 2024). DeepSeek-V3 achieves efficiency on par with the best versions of GPT-4o-0806 and Claude-3.5-Sonnet-1022, whereas surpassing different versions. In Table 5, we present the ablation results for the auxiliary-loss-free balancing technique.
Program synthesis with massive language models. Yarn: Efficient context window extension of massive language models. The fashions can then be run on your own hardware using instruments like ollama. With this AI mannequin, you can do practically the same things as with different fashions. However, it has the identical flexibility as other models, and you may ask it to elucidate things more broadly or adapt them to your needs. Combined with the framework of speculative decoding (Leviathan et al., 2023; Xia et al., 2023), it could possibly considerably speed up the decoding pace of the mannequin. Standardized exams embody AGIEval (Zhong et al., 2023). Note that AGIEval consists of both English and Chinese subsets. Table 8 presents the performance of these fashions in RewardBench (Lambert et al., 2024). DeepSeek-V3 achieves efficiency on par with the best versions of GPT-4o-0806 and Claude-3.5-Sonnet-1022, whereas surpassing different versions. In Table 5, we present the ablation results for the auxiliary-loss-free balancing technique.
In Table 4, we present the ablation outcomes for the MTP technique. From the desk, we are able to observe that the auxiliary-loss-free technique consistently achieves higher mannequin performance on most of the analysis benchmarks. To be particular, we validate the MTP technique on top of two baseline models throughout completely different scales. To be specific, in our experiments with 1B MoE fashions, the validation losses are: 2.258 (utilizing a sequence-clever auxiliary loss), 2.253 (using the auxiliary-loss-DeepSeek-LLM sequence of models.
댓글목록
등록된 댓글이 없습니다.